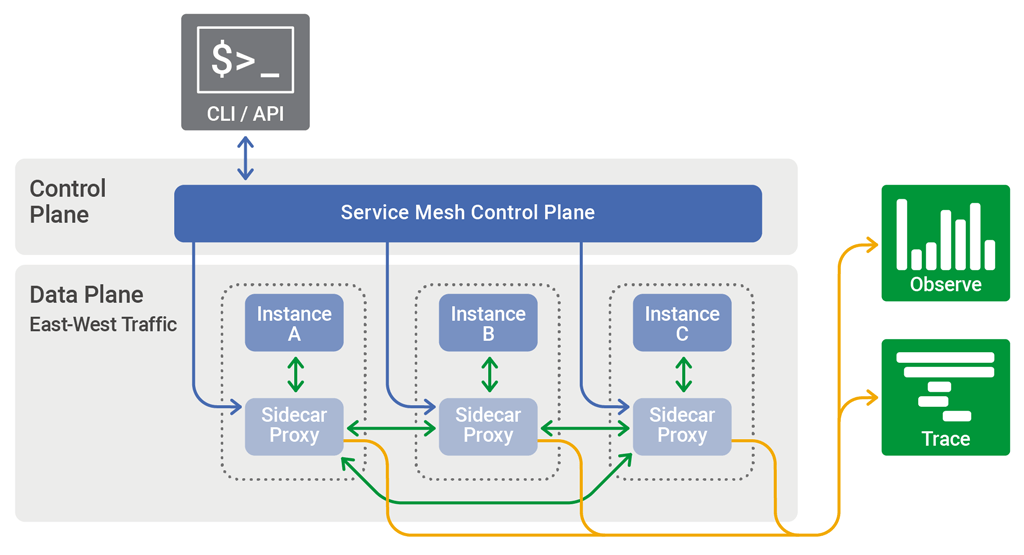
Docker基础命令
镜像相关
docker pull
docker pull 镜像名字 拉取远端的img,可以加版本,默认是latest
docker login
1 | docker login harbor.rrswl.com |
docker build
docker build 构建img
1 | docker build -t xxx:1.0.0 -f 指定dockerfile文件 . |
别漏了最后一个.,指定构建的上下文目录。不一定非要是当前目录。
–no-cache:构建时不要用缓存
docker images
docker images:显示本地有哪些镜像
docker rmi
docker rmi 镜像id 删除img
docker tag
1 | docker tag img_id 新的镜像名和版本 |
docker commit
docker commit -m ‘更新说明’ dockerid 新镜像的名字:可以保存对容器内镜像的修改,保存后会生成个新的image
把容器的改变提交为一个新镜像
底层使用git
docker image prune
删除游离镜像
commit 一个新的同名镜像,以前的镜像就会变为游离镜像
docker push
推送镜像到docker官方镜像仓库
1 | docker push docker.io/自己的用户名/镜像名:tag |
push之前要先登录
1 | docker login -u xxx -p xxxxx harbor-test.my.com |
push之前需要将镜像改名,加上用户名才能符合规范
1 | docker tag kubesphere/node-exporter:ks-v0.18.1 harbor-test.my.com/kubesphere/node-exporter:ks-v0.18.1 |
其他镜像仓库,修改docker.io为对应地址
docker export
导出一个容器的文件系统,作为一个tar包
1 | docker export -o nginx.tar 容器id |
docker import
把导出的tar包再导成一个镜像
这个镜像不能直接启动,需要知道这个镜像的启动命令
用docker inspect查看EntryPoint + CMD
或者docker ps –no-trunc 查看
docker save
把一个或多个镜像保存为tar文件
1 | docker save -o xxx.tar 镜像名 |
docker load
1 | docker load -i xxx.tar |
加载为镜像
容器运行相关
docker create
只创建,不启动
docker start
启动一个已经创建过的容器,是后台运行
docker pause
暂停一个容器
docker unpause
恢复一个暂停的容器,start不能启动一个暂停的容器
docker stop
退出容器,要用start起来
docker kill
kill也是停掉容器。和stop的区别是,kill是强杀。stop是优雅停机。
docker run
1 | docker run [OPTIONS] IMAGE [COMMAND] [ARG...] |
run 是create + start
-p
指定端口绑定
-P
随机端口绑定
–link可以用来链接2个容器,使得源容器(被链接的容器)和接收容器(主动去链接的容器)之间可以互相通信,并且接收容器可以获取源容器的一些数据,如源容器的环境变量。
–link 不推荐使用
–link
其中,name和id是源容器的name和id,alias是源容器在link下的别名。
把其他容器联进来使用,比如我们的java应用需要用到redis。可以用先启动一个redis容器,然后link进来。java容器可以ping通这个别名。
但是如果后来redis容器挂了,重启。ip变了之后,java容器不能再联通redis容器。因为java容器的hosts绑定了之前的
-d
-d是后台运行
docker run -p 8080:80 -d nginx 比如运行一个nginx -p的意识是将host主机的8080端口映射到容器的80端口 -d是守护进程的意思
-v 挂载
-v 主机的绝对路径:容器的绝对路径 绑定并挂载。小心空挂载
如果是 -v 不以/开头的路径:容器的绝对路径。 只绑定,不挂载。docker会自动管理,不会把他当成目录,而是当成卷
这种情况下,docker做的事情:
- 在主机目录/var/lib/docker/volumes创建指定名字的卷(具名卷)
- 把这个卷和容器内部目录绑定
- 容器启动以后,容器目录里的内容就在卷里面。都是同一份
建议:
- 开发测试,使用-v 绝对路径
- 生产用卷
–restart=always
--rm 用完自动删
docker ps
docker ps 查看当前正在运行的docker容器
docker ps -a 查看所有容器信息,包括之前运行过,已经停止的
docker ps -aq 只显示docker id
docker rm -f $(docker ps -aq) 删除所有容器
排查问题相关
docker logs
docker logs -f 容器id
每个容器的日志默认都会以 json-file 的格式存储于/var/lib/docker/containers/<容器id>/<容器id>-json.log 下
查看日志,也可以直接去/var/lib/docker/containers/ 具体容器挂载的目录下,直接看日志json格式(不建议这么做)
如果容器一直运行并且一直产生日志,容器日志会导致磁盘空间爆满,
全局设置限制容器日志大小su
1 | vim /etc/docker/daemon.json |
2
3
4
systemctl daemon-reload
重启docker
systemctl restart docker注意:设置的日志大小,只对新建的容器有效。
设置完成之后,需要删除容器,并重新启动容器,
docker attach
绑定的是控制台。一般不用。可能导致容器停止。
docker exec
docker exec -it 容器 /bin/sh
-u 0:0 root用户:root组
–privileged 超级权限,特权
docker inspect
查看详情
docker [container] inspect
docker image inspect
操作容器
docker cp
可以往容器里copy,也可以从docker里复制出来
1 | docker cp index.html mynginx:/usr/share/nginx/html |
或
1 | docker cp mynginx:/etc/nginx/nginx.conf nginx.conf |
原文件是文件:
- 目标文件不存在。则创建目标文件,内容为源文件的内容
- 目标文件不存在,且以/结尾。则报错
- 目标文件存在且是文件,则替换
- 目标文件存在且是目录。则将源文件复制到目录内
源文件是一个目录:
- 目标目录不存在。则创建目录,复制所有文件
- 目标目录存在,但是一个文件。报错
- 目标目录存在,且以/结尾,则将原文件夹内的文件复制
- 目标目录存在,且不以/结尾,则将源文件目录整个复制
docker diff
查看容器的变动
docker rm
docker rm 容器id 删除一个容器
docker update
更新容器配置
卷
docker volume
对docker的卷进行管理
/var/lib/docker/volumes